
适用于spaCy2.1版本的中文预训练模型,包括词向量、词性标注、依存分析和命名实体识别。
spaCy是最流行的开源NLP开发包之一,它有极快的处理速度,并且预置了 词性标注、句法依存分析、命名实体识别等多个自然语言处理的必备模型。 本包提供适用于spaCy 2.1的中文预训练模型,包括词向量、词性标注、依存 分析和命名实体识别,由汇智网整理提供。
下载后将解压到一个目录即可,例如假设解压到目录 /spacy/zh_model,目录结构如下:
/spacy/zh_model
| - meta.json # 模型描述信息
| - tokenizer
| - vocab # 词库目录
| - tagger # 词性标注模型
| - parser # 依存分析模型
| - ner # 命名实体识别模型
使用spaCy载入该模型目录即可。例如:
import spacy
nlp = spacy.load('/spacy/zh_model')
doc = nlp('西门子将努力参与中国的三峡工程建设。')
for token in doc:
print(token.text)
spaCy中文模型采用了中文维基语料预训练的300维词向量,共352217个词条。
例如,查看词向量表大小及维度:
import spacy
nlp = spacy.load('/spacy/zh_model')
print(nlp.vocab.vectors.shape)
print(nlp.vocab['北京'].vector)
结果如下:
(352217, 300)
[-0.136166 -0.339835 0.528109 0.417842 -0.093321 -0.42306 -0.475931
-0.125459 0.137432 -0.567229 0.242339 0.245993 -0.377495 -0.274273
...
0.238025 0.309567 -0.692431 -0.078103 -0.26816 0.051805 0.075192
-0.052902 0.376131 -0.221235 0.23855 -0.11685 0.40507 ]
spaCy中文词性标注模型采用Universal Dependency的中文语料库进行训练。
import spacy
nlp = spacy.load('/spacy/zh_model')
doc = nlp('西门子将努力参与中国的三峡工程建设。')
for token in doc:
print(token.text,token.pos_,token.tag_)
将得到如下的词性标注结果:
西门子 NNP
将 BB
努力 RB
参与 VV
中国 NNP
的 DEC
三峡工程 NN
建设 NN
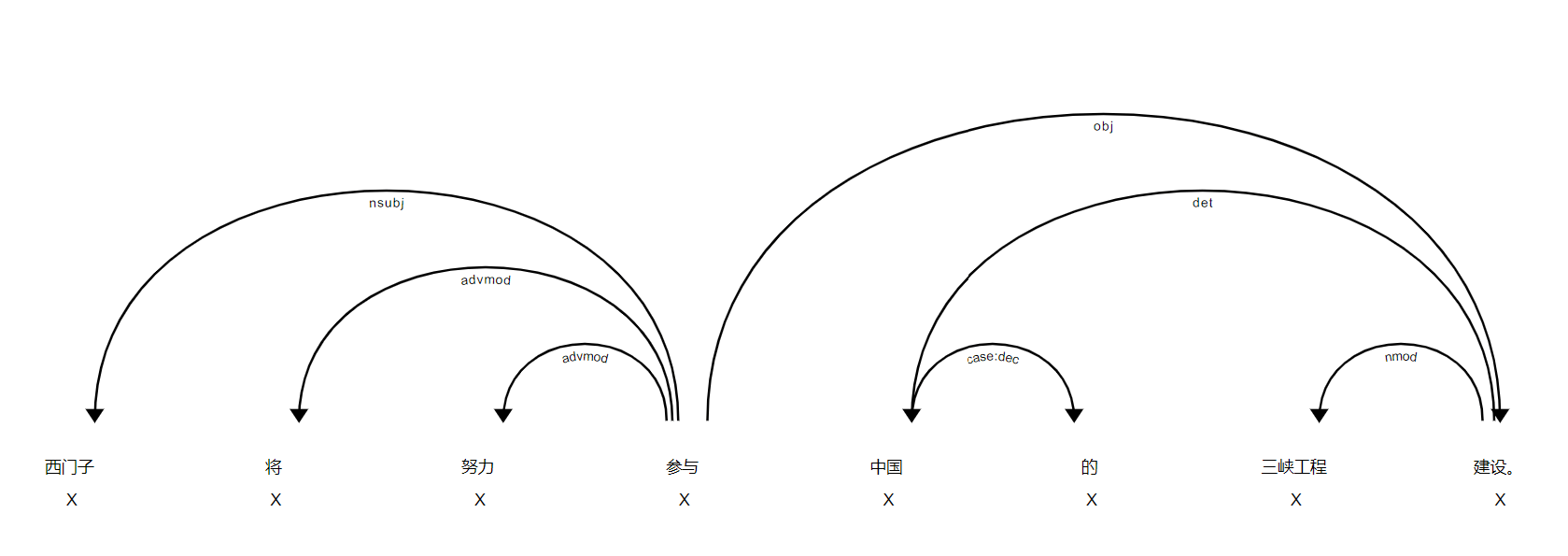
spaCy中文依存分析模型采用Universal Dependency的中文语料库进行训练。
例如,下面的代码输出各词条的文本、依赖关系以及其依赖的词条:
import spacy
nlp = spacy.load('/spacy/zh_model')
doc = nlp('西门子将努力参与中国的三峡工程建设。')
for token in doc:
print(token.text,token.dep_,token.head)
输出结果如下:
西门子 nsubj 参与
将 advmod 参与
努力 advmod 参与
参与 ROOT 参与
中国 det 建设
的 case:dec 中国
三峡工程 nmod 建设
建设 obj 参与
。 punct 参与
也可以使用spaCy内置的可视化工具:
from spacy import displacy
displacy.render(doc,type='dep')
结果如下:
spaCy中文NER模型采用ontonotes 5.0数据集训练。
例如:
import spacy
nlp = spacy.load('/spacy/zh_model')
doc = nlp('西门子将努力参与中国的三峡工程建设。')
for ent in doc.ents:
print(ent.text,ent.label_)
输出结果如下:
西门子 ORG
中国 GPE
三峡工程 FAC
也可以使用spaCy内置的可视化工具:
from spacy import displacy
displacy.render(doc,type='ent')
运行结果如下:

本站所提供软件包仅用于学习和研究,请依法合规使用。
本站所提供软件包均提供完整源码,使用前请认真阅读源代码和文档以确保充分理解软件包的设计与功能实现,本站不承担 因不当使用本站所提供软件包而造成的任何法律风险或财产损失责任。